This the multi-page printable view of this section. Click here to print.
Appendices
- 1: Appendix A: Configuration Parameter Reference
- 2: Appendix B: Security FAQ
- 3: Appendix C: Leveraging an API Gateway for GDPR Readiness
- 4: Appendix D: Architecture FAQ
- 5: Appendix E: Scalability
1 - Appendix A: Configuration Parameter Reference
APP_CIPHER: Database encryption cipher, options are AES-128-CBC or AES-256-CBC (default). Only change this if you are starting from a clean databaseAPP_DEBUG: When your application is in debug mode, detailed error messages with stack traces will be shown on every error that occurs within your application. If disabled, a simple generic error page is shownAPP_ENV: This may determine how various services behave in your applicationAPP_KEY: This key is used by the application for encryption and should be set to a random, 32 character string, otherwise these encrypted strings will not be safe. Use ‘php artisan key:generate’ to generate a new key. Please do this before deploying an application!APP_LOCALE: The application locale determines the default locale that will be used by the translation service provider. Currently only ‘en’ (English) is supportedAPP_LOG: This setting controls the placement and rotation of the log file used by the applicationAPP_LOG_LEVEL: The setting controls the amount and severity of the information logged by the application. This is hierarchical and goes in the following order: DEBUG -> INFO -> NOTICE -> WARNING -> ERROR -> CRITICAL -> ALERT -> EMERGENCY. If you set log level to WARNING then all WARNING, ERROR, CRITICAL, ALERT, and EMERGENCY will be logged. Setting log level to DEBUG will log everything. Default is WARNING [‘APP_NAME’]=“This value is used when the framework needs to place the application’s name in a notification or any other location as required by the application or its packagesAPP_TIMEZONE: Here you may specify the default timezone for your application, which will be used by the PHP date and date-time functionsAPP_URL: This URL is used by the console to properly generate URLs when using the Artisan command line tool. You should set this to the root of your application so that it is used when running Artisan tasksDF_LANDING_PAGE: This is the starting point (page, application, etc.) when a browser points to the server root URL
Database settings
DB_CONNECTION: This corresponds to the driver that will be supporting connections to the system database serverDB_HOST: The hostname or IP address of the system database serverDB_PORT: The connection port for the host given, or blank if the provider default is usedDB_DATABASE: The database name to connect to and where to place the system tablesDB_USERNAME: Credentials for the system database connection if requiredDB_PASSWORD: Credentials for the system database connection if requiredDB_CHARSET: The character set override if required. Defaults use utf8, except utf8mb4 for MySQL-based databases - may cause problems for pre-5.7.7 (MySQL) or pre-10.2.2 (MariaDB), if so, use utf8DB_COLLATION: The character set collation override if required. Defaults use utf8_unicode_ci, except utf8mb4_unicode_ci for MySQL-based database - may cause problems for pre-5.7.7 (MySQL) or pre-10.2.2 (MariaDB), if so, use utf8_unicode_ciDB_MAX_RECORDS_RETURNED: This is the default number of records to return at once for database queriesDF_SQLITE_STORAGE: This is the default location to store SQLite3 database files
FreeTDS configuration (Linux and OS X only)
DF_FREETDS_DUMP: Enabling and location of dump file, defaults to disabled or default freetds.conf settingDF_FREETDS_DUMPCONFIG: Location of connection dump file, defaults to disabled
Cache
CACHE_DRIVER: What type of driver or connection to use for cache storageCACHE_DEFAULT_TTL: Default cache time-to-live, defaults to 300CACHE_PREFIX: A prefix used for all cache written out from this installationCACHE_PATH: The path to a folder where the system cache information will be storedCACHE_TABLE: The database table name where cached information will be storedREDIS_CLIENT: What type of php extension to use for Redis cache storageCACHE_HOST: The hostname or IP address of the memcached or redis serverCACHE_PORT: The connection port for the host given, or blank if the provider default is usedCACHE_USERNAME: Credentials for the service if requiredCACHE_PASSWORD: Credentials for the service if requiredCACHE_PERSISTENT_ID: Memcached persistent ID settingCACHE_WEIGHT: Memcached weight settingCACHE_DATABASE: The desired Redis database number between 0 and 16 (or the limit set in your redis.conf file
Limits
LIMIT_CACHE_DRIVER: What type of driver or connection to use for limit cache storageLIMIT_CACHE_PREFIX: A prefix used for all cache written out from this installationLIMIT_CACHE_PATH: Path to a folder where limit tracking information will be storedLIMIT_CACHE_TABLE: The database table name where limit tracking information will be storedLIMIT_CACHE_HOST: The hostname or IP address of the redis serverLIMIT_CACHE_PORT: The connection port for the host given, or blank if the provider default is usedLIMIT_CACHE_USERNAME: Credentials for the service if requiredLIMIT_CACHE_PASSWORD: Credentials for the service if requiredLIMIT_CACHE_PERSISTENT_ID: Memcached persistent ID settingLIMIT_CACHE_WEIGHT: Memcached weight settingLIMIT_CACHE_DATABASE: The desired Redis database number between 0 and 16 (or the limit set in your redis.conf file
Queuing
QUEUE_DRIVER: What type of driver or connection to use for queuing jobs on the serverQUEUE_NAME: Name of the queue to use, defaults to ‘default’QUEUE_RETRY_AFTER: Number of seconds after to retry a failed job, defaults to 90QUEUE_TABLE: The database table used to store the queued jobsQUEUE_HOST: The hostname or IP address of the beanstalkd or redis serverQUEUE_PORT: The connection port for the host given, or blank if the provider default is usedQUEUE_DATABASE: The desired Redis database number between 0 and 16 (or the limit set in your redis.conf fileQUEUE_PASSWORD: Credentials for the service if requiredSQS_KEY: AWS credentialsSQS_SECRET: AWS credentialsSQS_REGION: AWS storage regionSQS_PREFIX: AWS SQS specific prefix for queued jobs
Event Broadcasting
BROADCAST_DRIVER: What type of driver or connection to use for broadcasting events from the serverPUSHER_APP_ID:PUSHER_APP_KEY:PUSHER_APP_SECRET:BROADCAST_HOST: The hostname or IP address of the redis serverBROADCAST_PORT: The connection port for the host given, or blank if the provider default is usedBROADCAST_DATABASE: The desired Redis database number between 0 and 16 (or the limit set in your redis.conf fileBROADCAST_PASSWORD: Credentials for the service if required
User Management
DF_LOGIN_ATTRIBUTE: By default DreamFactory uses an email address for user authentication. You can change this to use username instead by setting this to ‘username’DF_CONFIRM_CODE_LENGTH: New user confirmation code length. Max/Default is 32. Minimum is 5DF_CONFIRM_CODE_TTL: Confirmation code expiration. Default is 1440 minutes (24 hours)DF_ALLOW_FOREVER_SESSIONS: falseJWT_SECRET: If a separate encryption salt is required for JSON Web Tokens, place it here. Defaults to the APP_KEY settingDF_JWT_TTL: The time-to-live for JSON Web Tokens, i.e. how long each token will remain valid to useDF_JWT_REFRESH_TTL: The time allowed in which a JSON Web Token can be refreshed from its originationDF_CONFIRM_RESET_URL: Application path to where password resets are to be handledDF_CONFIRM_INVITE_URL: Application path to where invited users are to be handledDF_CONFIRM_REGISTER_URL: Application path to where user registrations are to be handled
Server-side Scripting
DF_SCRIPTING_DISABLE: To disable all server-side scripting set this to ‘all’, or comma-delimited list of v8js, nodejs, python, and/or php to disable individuallyDF_NODEJS_PATH: The system will try to detect the executable path, but in some environments it is best to set the path to the installed Node.js executableDF_PYTHON_PATH: The system will try to detect the executable path, but in some environments it is best to set the path to the installed Python executable
API
DF_API_ROUTE_PREFIX: By default, API calls take the form of http://<server_name>/<api_route_prefix>/v<version_number>DF_STATUS_ROUTE_PREFIX: By default, API calls take the form of http://<server_name>/[<status_route_prefix>/]statusDF_STORAGE_ROUTE_PREFIX: By default, API calls take the form of http://<server_name>/[<storage_route_prefix>/]<storage_service_name>/<file_path>DF_XML_ROOT: XML root tag for HTTP responsesDF_ALWAYS_WRAP_RESOURCES: Most API calls return a resource array or a single resource, if array, do we wrap it?DF_RESOURCE_WRAPPER: Most API calls return a resource array or a single resource, if array, what do we wrap it with?DF_CONTENT_TYPE: Default content-type of response when accepts header is missing or empty
Storage
DF_FILE_CHUNK_SIZE: File chunk size for downloadable files in bytes. Default is 10MB
Other settings
DF_PACKAGE_PATH: Path to a package file, folder, or URL to import during instance launchDF_LOOKUP_MODIFIERS: Lookup management, comma-delimited list of allowed lookup modifying functions like urlencode, trim, etc. Note: Setting this will disable a large list of modifiers already internally configuredDF_INSTALL: This designates from where or how this instance of the application was installed, i.e. Bitnami, GitHub, DockerHub, etc.
2 - Appendix B: Security FAQ
Appendix B. Security FAQ
What is the DreamFactory Platform?
- DreamFactory is an on-premise platform for instantly creating and managing APIs, currently used across the healthcare, finance, telecommunications, banking, government, & manufacturing industries.
- DreamFactory’s product is designed with security in mind to create APIs that maintain confidentiality of customer data, allow for restricted access to APIs based on administrator-defined privilege levels, and provide uninterrupted availability of the data.
- DreamFactory does not store or maintain customer data associated with customer databases or customer generated APIs using its software.
- DreamFactory software and product updates are downloaded by the customer and data is transmitted using secure HTTPS/TLS protocols.
- Access to customer data is only through express permission from the customer. This is rarely requested and only in circumstances where DreamFactory product support is directly assisting the customer with debugging and/or product support.
- No sensitive, confidential, or other protected data is stored by DreamFactory beyond contact and billing information required for business transactions.
Who is responsible for developing the DreamFactory platform?
- DreamFactory’s internal development team collaborates closely with a trusted third party for technical support and coding for product updates. During this process, third parties have no access to customer data and all lines of code are audited and individually reviewed by DreamFactory’s Chief Technical Officer (CTO).
Does DreamFactory employ any staff members focused specifically on security?
- DreamFactory has a CISSP(TM) actively involved in its security assessment, procedures and review. Moreover, the business staffs Cybersecurity Masters trained leaders to support their approach.
- The software is open source and fully available for testing, at source level, by its customers. Currently the business satisfies the needs of several Fortune 100 customers.
- Our incident response plan that brings together key company representatives from the leadership, legal, and technical teams for rapid assessment and remediation. It includes business continuity and disaster response elements as well as notification processes to ensure customers are fully informed.
Is DreamFactory certified to be in compliance with security frameworks such as FISMA and HIPAA?
- The DreamFactory security policy framework is built on the Cloud Security Alliance’s (CSA’s) Consensus Assessments Initiative Questionnaire (CAIQ v3.0.1) which maps to other commonly utilized compliance frameworks including SOC, COBIT, FedRAMP, HITECH, ISO, and NIST.
- DreamFactory uses industry standard cybersecurity controls to protect against all of the OWASP Top 10 web application security risks.
- Product updates and improvements follow a standardized SDLC process, including DevSecOps under the supervision of our CTO.
- Our policies are designed in compliance with key privacy regulations such as GDPR, PIPEDA, COPPA, HIPAA and FERPA.
How does DreamFactory prevent information compromise?
- DreamFactory software uses an integrated defense in depth to provide customers configurable tools secure their information. This defense starts with access keys that are individually generated and associated with each API.
- Beyond basic authentication, DreamFactory supports LDAP, Active Directory, and SAML-based SSO.
- Customers can create and assign roles to API keys, and delegate/manage custom permissions as well as mapping AD/LDAP groups to roles.
- Other controls include the ability for customers to set rate limiting (by minutes, hours, or days), logging, and reporting preferences, and individually assigning them to users. Real-time traffic auditing is possible through Elasticsearch, Logstash, and Kibana or Grafana dashboards.
- Collectively, this approach allows customers to instantly see who has accessed their data, and individually adjust their access by role or user profile.
- DreamFactory 3.0 includes several new security features including API lifecycle auditing and restricted administrator controls.
How does DreamFactory prevent the misuse of customer information?
- Our customers fully own and control their own data, so there is virtually no way for a DreamFactory employee to access a customer’s data.
- Employees that disclose or misuse confidential company or customer data are subject to disciplinary action up to and including termination.
- All DreamFactory employees receive full background checks during the hiring process, and access to the product is strictly controlled by our CTO.
- Employee role changes and termination events include an immediate review of access which is assigned on a need to know basis commensurate with employee responsibilities. Terminated employees immediately lose access to email, files, and use of company systems and networks.
- DreamFactory utilizes a Password Manager system that enforces the updated recommendations in NIST 800-63-3, and employees may not share passwords or access. This is supervised through the use of logging and reporting controls.
How does DreamFactory prevent accidental information disclosure?
- All DreamFactory employees receive cybersecurity training during onboarding and periodically throughout the year.
- Role based permissions are employed and access is granted based on individual responsibilities and time required.
- Internal company data is secured in the cloud through GSuite’s Data Loss Prevention (DLP) tools, and employees are granted access on a need to know basis based on their role within DreamFactory.
What DreamFactory safeguards are in place to prevent the loss of data?
- Employees have limited access to DreamFactory information and no access to customer data.
- Internal company data is secured in the cloud through GSuite’s Data Loss Prevention (DLP) tools, and employees are granted access on a need to know basis based on their role within DreamFactory.
- DreamFactory security policies do not allow employees to use external media.
- DreamFactory utilizes MacOS systems and the included Apple FileVault product to encrypt all data at rest. Should a laptop be stolen, all data will remain encrypted and can be remotely wiped. Customer data is never saved on company systems and devices.
- Dreamfactory intellectual property and proprietary product information is backed up in secure cloud enclaves and managed by our CTO and technical staff.
- Two-Factor Authentication is required for access to company data.
What DreamFactory safeguards are in place to alleviate privacy concerns?
- Customer privacy is a paramount concern for DreamFactory. This focus goes to the heart of our product which allows customers to retain full control of their data, as well as rapidly create and manage personalized controls.
- As a rule, DreamFactory collects only the information absolutely required, stores it only as long as it is needed, and shares it with the absolute minimum number of employees.
- Our policies are designed in compliance with key privacy regulations such as GDPR, PIPEDA, COPPA, HIPAA and FERPA.
- Our goal is to be fully transparent and responsive with our customers on privacy issues.
What is the recommended application hardening document for production deployment of DreamFactory?
DreamFactory is an HTTP-based platform which supports a wide array of operating systems (both Windows and Linux) and web servers (notably Nginx, Apache, and IIs), and therefore administrators are encouraged to follow any of the many available hardening resources for general guidance. Hardening in the context of DreamFactory would primarily be a result of software-level hardening, and several best practices are presented in the next answer. We’re happy to provide further guidance on this matter after learning more about the target operating system.
How should DreamFactory administrators ensure the data security and integrity for production deployment?
Data security and integrity is ensured by following key best practices associated with building any HTTP-based API solution:
- Ensure the server software (Nginx, PHP, etc) and associated dependencies are updated to reduce the possibility of third-party intrusion through disclosed exploits.
- Stay up to date with DreamFactory correspondence regarding any potential platform security issues.
- Periodically audit the DreamFactory role definitions to ensure proper configuration.
- Periodically audit database user accounts used for API generation and communication to ensure proper configuration. In this case, proper configuration is defined as ensuring each user account is assigned a minimally viable set of privileges required for the API to function is desired.
- Periodically audit API keys, disabling or deleting keys no longer in active use.
- If applicable (requires Enterprise license), use DreamFactory’s logging integration to send traffic logs to a real-time monitoring solution such as Elastic Stack or Splunk.
- If applicable (requires Enterprise license), use DreamFactory’s restricted administrator feature to limit administrator privileges.
What is the method for DreamFactory Encryption for data at Rest ? is it enabled by default or do we have to do it manually?
DreamFactory does not by default store any API data as it passes through the platform. Some connectors offer an API data caching option which will improve performance, however the administrator must explicitly enable this option. Should caching be enabled, data can be stored in one of several supported caching solutions, including Redis and Memcached. Solutions such as Redis are designed to be accessed by “trusted clients within trusted environments”, as described by for instance the Redis documentation: https://redis.io/topics/security.
How does DreamFactory encrypt data in transit? Is it enabled by default or are additional steps required?
DreamFactory plugs into a variety of third-party data sources, including databases such as Microsoft SQL Server and MySQL, file systems such as S3, and third-party HTTP APIs such as Salesforce, Intercom, and Twitter. DreamFactory will then serve as a conduit for clients desiring to interacting with these data sources via an HTTP-based API. DreamFactory runs atop a standard web server such as Apache or Nginx, both of which support SSL-based communication. Provided HTTPS is enabled, all correspondence between DreamFactory and the respective clients will be encrypted.
Lost/Forgotten Admin UI Password
I lost my DreamFactory administrator password. How can I recover it?
DreamFactory uses one-way encryption for passwords, meaning that once they are encrypted they cannot be decrypted. If email-based password recovery has not been configured, you can create a new administrator account by logging into the terminal console included with all versions of DreamFactory. To do so, begin by SSHing into your DreamFactory server. Next, navigate to the DreamFactory root directory. For those who used an automated DreamFactory installer, the root directory will be /opt/dreamfactory. The path will vary in accordance to other installers.
Next, enter the terminal console:
$ php artisan tinker
Psy Shell v0.9.12 (PHP 7.2.28 — cli) by Justin Hileman
Use the following command to retrieve the desired administrator account. You’ll need to swap out the placeholder email address with the actual administrator address:
>>> $u = \DreamFactory\Core\Models\User::where('email', '[email protected]')->first();
Change the password to the desired value and save the results:
>>> $u->password = 'secret';
=> "secret"
>>> $u->save();
=> true
You can confirm the password has been encrypted (hashed) by referencing the $u object’s password attribute:
>>> $u->password
=> "$2y$10$jtlt8D8fHWzgoosAV/P6m.w459QE6ntNfbXo.1x6V9GPXGVT7IFfm"
Exit the console, and return to the browser to login using the new password:
>>> exit
3 - Appendix C: Leveraging an API Gateway for GDPR Readiness
Executive Overview
API platforms are recognized as the engine driving digital transformation, enabling the externalization of IT assets across enterprise and customers boundaries. By adopting this new architecture, enterprises can transform the way they do business with unprecedented time to value and entirely new engagement models to monetize IT as a business.
What is less promoted, however, is the power of full-lifecycle API platforms in addressing regulatory compliance requirements. There is a common thread in IT’s modernization and regulatory compliance agendas, being the repackaging of data systems as a shared resource that is able to support a myriad of new consumption models. The cornerstone of this repackaging is implementing Data Gateways to enable and manage secure and monitorable access to enterprise data systems.
This paper outlines how to leverage an API platform to retrofit existing infrastructure for “GDPR readiness”, essentially as a byproduct of implementing a modern architecture for digital transformation.
General Data Protection Regulation (GDPR)
While having a simple stated goal of returning control of any European citizen’s private data back to the consumer- the implications spread far past the EU and touch every organization that handles consumer data directly or through a partner. The penalties for non-compliance are severe, potentially 4% of global revenue - per incident! So as you might guess, companies are paying close attention to the regulation and scrambling to ensure compliance by the rapidly approaching start date of May 25, 2018.
PII (Personally Identifiable Information)
PII is the specific data that GDPR regulates. PII is data that can be used to distinguish an identity and includes social security numbers, date and place of birth, mother’s maiden name, biometric records, etc. PII also includes logged behavioral data such as data collected from a user’s web session.
Data Protection Officer (DPO)
A data protection officer is a new leadership role required by the General Data Protection regulation for companies that process/store large amounts of personal data as well as any public authority (national, state, or local government body). DPO’s are responsible for overseeing the organization’s data protection strategy and implementation to ensure compliance with GDPR requirements.
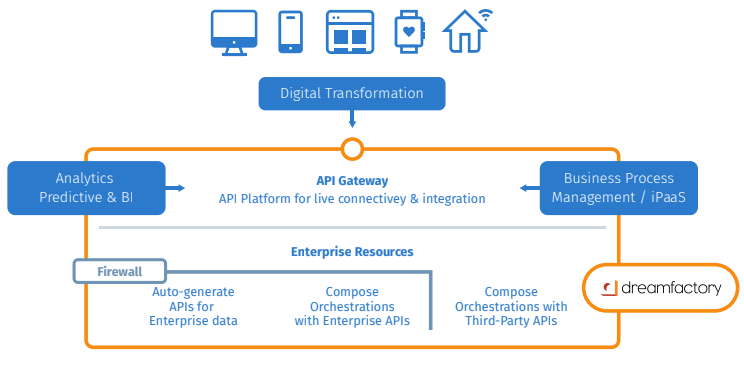
API Automation Platform
As the name suggests, API Automation platforms automate the creation of APIs and provide a gateway for secure access to data endpoints. A full lifecycle platform combines API management, API generation, and API orchestration into a single runtime. Also referred to as Data Gateways, they provide discovery, access, and control mechanisms surrounding enterprise data that needs to be shared with external consumers. Ideally, a Data Gateway is non-disruptive to existing infrastructure - meaning that it can be retrofitted versus “rip and replace” approach.
A full lifecycle data gateway automates several key functions:
- Facilitating the creation of bidirectional data APIs for CRUD operations
- Providing a secure gateway to control access, track, log and report on data usage.
- Discovering key aspects of data to generate catalogs and inventory
- Orchestrating APIs to chain operations within and between data systems.
- Packaging and containerizing data access for portability
The remainder of the document looks at specific requirements in GDPR and illustrates how the DreamFactory API platform can help you bake in GDPR readiness into your infrastructure. DreamFactory’s API platform is unique in that it is the only “plug and play” platform, automatically generating a data gateway for any data resource.
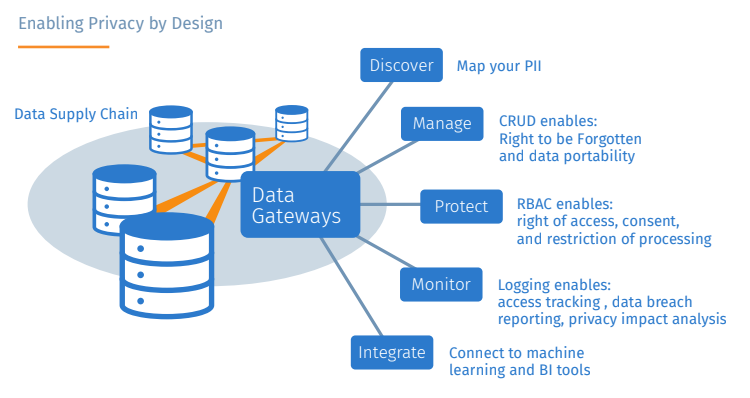
Right to be forgotten
This is a primary requirement and allows consumers to demand that their private data be deleted. To be able to do this in a timely manner an organization needs to know where all instances of this data exist in their internal systems as well as the partner ecosystems (data supply chain). Capabilities of DreamFactory’s Data Gateway relevant to “right to be forgotten” include:
- Auto-generation of APIs for any data resource, SQL, NoSQL, cloud storage, and commercial software systems such as Salesforce.com. Regardless of how or where you structure your data, DreamFactory provides a cons istent and reusable interface for on-demand CRUD operations, including record deletion.
- Data Cataloging. Dreamfactory automatically discovers and catalogs all of the assets of a data resource including metadata, stored procedures, and data relationships providing you with a holistic view of your data assets from a single pane of glass.
- Data Mesh. DreamFactory allows you to create virtual data relationships between databases and perform operations on all of them in a single API call.
- Role based access control. This allows your data supply chain to securely share PII with their partners and determine which operations can be performed on it.
- Pre/Post processing of API calls allows you to notify other systems of change
- Provide access to everything via REST to ensure standards based integration with analysis and workflow systems.
Moreover, DreamFactory is non-disruptive to existing infrastructure and easily bolts-on to retrofit existing systems for compliance.
Data Portability
Consumers have the right to move their data between vendors, and a vendor is obligated to provide this data to them in a timely manner. An example would be a customer can demand that their PII from one online banking vendor be transferred to another.
DreamFactory normalizes the interface to data. Regardless of how (SQL, NoSQL, storage) or where (cloud, on-prem) it persists you can expose it to data consumers as a single reusable API. This enables external systems to connect to the data using the same interface regardless of its underlying structure or location.
One important capability of DreamFactory’s gateways is that it handles all of the firewall plumbing required to access on-prem systems in cloud portals, providing a secure access mechanism across the data supply chain. Governance
As with any business critical regulation, enterprises need to gauge and track compliance. GDPR places increased emphasis on governance as the penalties can be so severe as to jeopardize the viability of a company.
DreamFactory bakes compliance readiness into the gateway between your data and all of the consumers of your data, with:
- Role based access control at various levels of granularity (e.g. app, record)
- Logging of all API calls accessing data records
- Limiting of API Calls to preemptively protect against attacks
- Reporting on all data activity
What databases are we talking about?
The DreamFactory platform automatically creates RESTified Data Gateways for the following databases:

As of the publication date of this paper, a SAP Hana integration is in late beta, while GraphQL support is additonally offered.
A full list of DreamFactory’s database connections can be seen here. The scope of platform capabilities, including SOAP to REST, EXCEL to REST, as well as integration with SMS, push notifications, Apple/Google technologies and more can be viewed here.
Summary
Progressive organizations are re-architecting their infrastructure with API platforms to get ahead of the competition. By taking this approach, enterprises have been able to share their data assets safely with any data consumer they need to support - whether to turbo charge new mobile and web app ecosystems, integrate cross-enterprise data, or create new business opportunities with partners & customers.
Now, with GDPR, there is an emerging and mission critical consumer of enterprise data that an API platform can support: the Data Protection Officer.
The DreamFactory Data Gateway is unique in that it is a unified runtime that automatically enables, controls, and monitors access for any enterprise data system.
To see how DreamFactory can help your organization, please request a demo to see how your digital transformation initiatives can be both automated and readied for GDPR regulations.
4 - Appendix D: Architecture FAQ
Basic System Architecture
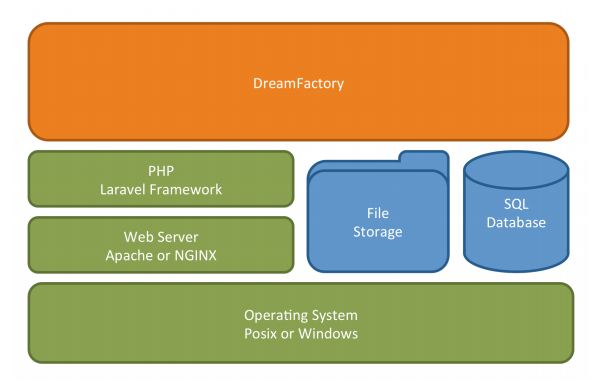
DreamFactory is an open source REST API backend that provides RESTful services for building mobile, web, and IoT applications. In technical terms, DreamFactory is a runtime application that runs on a web server similar to a website running on a traditional LAMP server.
In fact, as a base, we require a hosting web server like Apache, NGINX, or IIS. DreamFactory is written in PHP and requires access to a default SQL database for saving configuration. Depending on configuration for caching, etc. it may or may not need access to the file system for local storage. If pre- and/or post-process scripting is desired, access to V8Js or Node.Js may also be required. It runs on most Linux distributions (Ubuntu, Red Hat, CentOS, etc.), Apple Mac OS X, and Microsoft Windows.
Installation options are highly flexible. You can install DreamFactory on your IaaS cloud, PaaS provider, as a Docker container, on premises server, or a laptop. Installer packages are available, or the DreamFactory source code is available under the Apache License at GitHub.
DreamFactory Components
The DreamFactory application can logically be divided into several operational components. While these components are logical and do not necessarily represent the code structure itself, they are useful in discussing the subsystems and functionality of the application, as well as the anatomy of the API call later on.
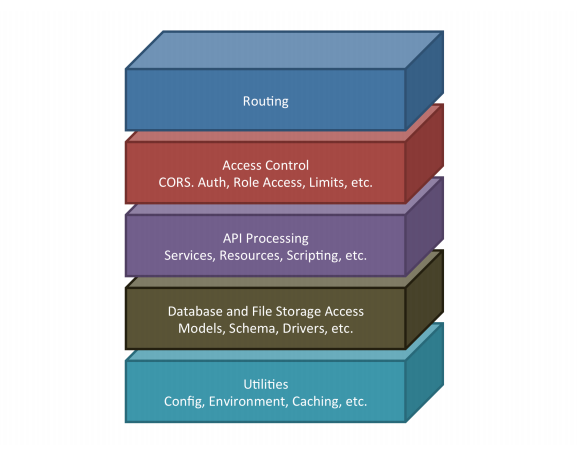
Routing
Routing sets up the supported HTTP interfaces to the system. In tandem with Controllers, this component controls the flow of the calls through the system. Controllers are essentially groups of routes or HTTP calls that share some logical handling and are paired with a set of access control components. There are essentially three controllers that the routing component can hand the call off to.
• Splash Controller - This handles the initial load and setup states of the system. It also routes web traffic to the default web application (i.e. Launchpad), where users can login and access other configured applications like the admin console, etc.
• Storage Controller - This handles direct file access to any file services where folders have been made public through configuration. Files are requested via the service name and the full file path relative to that service. The file contents are returned directly to the client. This is primarily used for running applications hosted on the DreamFactory instance.
• REST Controller - This is the main controller for the API, it handles the versioning of the API and routing to the various installed services via a Service Handler. It also handles any system exceptions and response formatting. The Service Handler communicates generically with all services through a service request and response object.
Access Control
Access Control is made up of middleware, groups of checks and balances that can be used to control access to various parts of the application. The services and resources for Access Control consist of the following:
• System status checks • Cross-Origin Resource Sharing (CORS) configuration allowances • Authentication via user login, API keys, and/or session tokens • Authorization via assigned user and app role access • And usage limit tracking and restrictions
If any of these checks fail, the call is denied and the correct error response is sent back to the client; no further processing is done. If all of these checks pass, the call is allowed to continue on to one of the handling controllers, which routes the call for the appropriate API processing.
API Processing
At this point the API can be broken down further into logical components that we call Services. Services can be anything from a system configuration handler (i.e. the “system” service), to a database access point, or a remote web service. Service types can be dynamically added to the system to expand service offerings, but many are included out of the box and are list here.
Server-side Scripting
Part of this REST handling by the services includes server-side scripting. Each API endpoint, be it a Service endpoint, or a subtending Resource endpoint, triggers two processing events, one for pre-process and one for post-process. Each event can be scripted to alter the request (pre) or response (post), perform extra logic including additional calls to other services on the instance or external calls, as well as halt execution and throw exceptions. Scripting can be used for formula fields, field validations, workflow triggers, access control, custom services, and usage limits. The role-based access controls have separate settings that govern data access for both client-side applications and server-side scripts. This capability enables server-side scripts to safely perform special operations that are not available from the client-side REST API.
The event scripting all happens in the context of the original API call. Therefore, event scripts block further execution of the API call until finished.
DreamFactory uses the V8 Engine developed by Google to run server-side code written in JavaScript. The V8 engine is sandboxed, so server side scripts cannot interfere with other system operations or resources.
In 2.0, DreamFactory also provides access to use Node.js and PHP as a server-side scripting environment. These environments are not sandboxed however and care must be taken when used.
Database and File Storage Access
Many of the services mentioned above eventually need to access some data or file store or communicate with a remote process or server. DreamFactory takes advantage of many available open-source packages, SDKs and compiled drivers to access these other resources.
In the case of database accesses, DreamFactory utilizes PDO drivers for SQL databases, as well as, other compiled drivers and extensions like MongoDB, and even HTTP wrapper classes for databases like CouchDB that provide a HTTP interface.
DreamFactory provides internal models and schema access for frequently used data components, particularly the system configuration components. The most frequently used are also cached to reduce database transactions.
A DreamFactory instance may utilize local file storage or various other storage options such as cloud-based storage. DreamFactory utilizes generic file access utilities that support a majority of the storage options, thus giving the system, and thus the API, a consistent way to access file storage.
Anatomy of an API Call
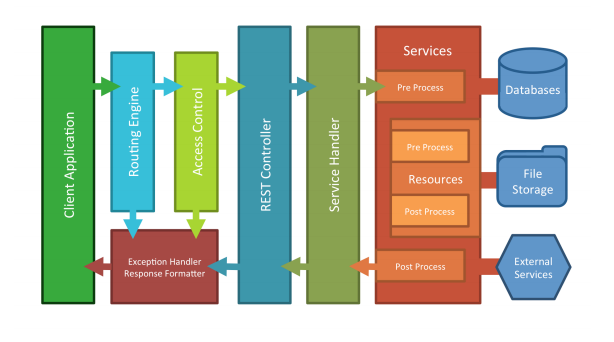
Anatomy of a Storage Call
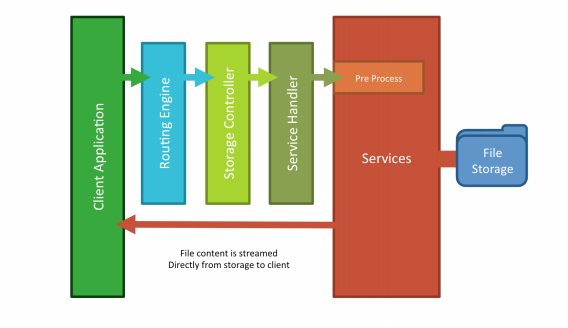
In Conclusion
DreamFactory is designed to be secure, simple to use, easy to customize, and dynamically expandable to meet most of your API needs. Reach out to the DreamFactory engineering team if you have additional questions of concerns.
5 - Appendix E: Scalability
Before we dive into the details, the most important thing to know is that DreamFactory is a configurable LAMP stack running PHP. As far as the server is concerned, DreamFactory looks like a website written in WordPress or Drupal. Instead of delivering HTML pages, DreamFactory delivers JSON documents, but otherwise the scaling requirements are similar.
Instead of using traditional session management, where the server maintains the state of the application, DreamFactory handles session management in a stateless manner, not requiring the server to maintain any application state. This makes horizontal scaling a breeze, as you’ll see below. For demanding deployments, we suggest using NGINX, more on that later.
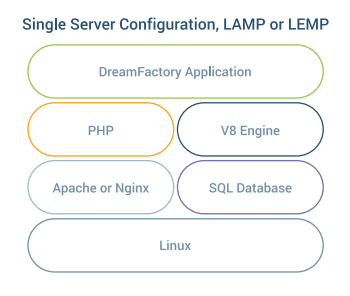
This is important because you can apply all the standard things you already know about scaling simple websites directly to scaling DreamFactory. This is not an accident. It makes DreamFactory easy to install on any server and easy to scale for massive deployments of mobile applications and Internet of Things (IoT) devices.
Vertical Scaling
You can vertically scale DreamFactory on a single server through the addition of extra processing power, extra memory, better network connectivity, and more hard disk space. This section discusses how vertical scaling and server configuration can impact performance.
By increasing server processor speed, number of processors, and RAM, you can improve the performance of the DreamFactory engine. Processor speed will especially improve round-‐trip response times. In our testing, DreamFactory can usually respond to a single service request in 100 to 200 milliseconds.
The other important characteristic is the number of simultaneous requests that DreamFactory can handle. On a single server with vertical scaling, this will depend on processor speed and available RAM to support multiple processes running at the same time. Network throughput is important for both round-‐trip time and handling a large number of simultaneous transactions.
Default SQL Database
Each DreamFactory instance has a default SQL database that is used to store information about users, roles, services, and other objects required to run the platform. The default Bitnami installation package includes a default SQL database, but you can also hook up any other database for this purpose. When this database is brought online, DreamFactory will create the additional system tables that are needed to manage the platform.
DreamFactory also stores server-‐side scripts in this default database. These scripts can be written in JavaScript or PHP to customize either the request or response of the API calls running through the engine. DreamFactory uses the V8 engine to execute JavaScript. This allows developers to use JavaScript both on the client and on the server and call the API from either side of the stack. The V8 engine is included in the Bitnami installers and must exist for server-‐side scripting to work.
Developers can also create tables on the default database for their own projects. Based on application requirements, mobile projects can query this database in various ways, and this activity can impact performance. The DreamFactory user records are also stored in the default database. Anything that you do to boost the performance of this database will increase the speed of the admin console and developer applications.
Local File Storage
Each DreamFactory instance also needs some file storage for HTML5 web application hosting. Each application is given a folder where the developer might store HTML files, graphic images, CSS style sheets, JavaScript files, etc. Native applications might store other documents or resources in local storage for simple download. The size and access speed of the local file system will impact application performance just like a normal web site.
Persistent Storage
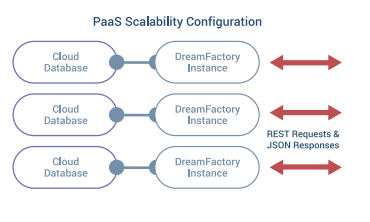
By default, DreamFactory uses persistent local storage for two things: system-‐wide cache data and hosted application files and resources. Many of the Platform as a Service (PaaS) systems such as Pivotal, Bluemix, Heroku, and OpenShift do not support persistent local storage.
For these systems, you need to configure DreamFactory to use memory-‐based cache storage such as Memcached or Redis. You also need to create a remote cloud storage service such as S3, Azure Blob, Rackspace etc. to store your application files. You can easily configure DreamFactory to use a memory-based cache via the config files.
The database for PaaS needs to be a remote SQL database like ClearDB or whatever the vendor recommends. If you use the local file system to create files at runtime these will disappear when the PaaS image is restarted or when multiple instances are scaled. Working with PaaS is discussed in greater detail under the cloud scaling section, below.
External Data Sources
You can hook up any number of external data sources to DreamFactory. DreamFactory currently supports MySQL, PostgreSQL, Oracle, SQL Server, DB2, S3, MongoDB, DynamoDB, CouchDB, Cloudant, and more. Some of the NoSQL databases are specifically designed for massive scalability on clustered hardware. You can hook up any SQL database running in your data center in order to mobilize legacy data. You can also hook up cloud databases like DynamoDB and Azure Tables.
DreamFactory acts as a proxy for these external systems. DreamFactory will inherit the performance characteristics of the database, with some additional overhead for each REST API call. DreamFactory adds a security layer, a customization layer, normalizes the web services, and implements role-based access control for each service. The scalability of these external data sources will depend on service level agreements with your cloud vendor, the hardware behind database clustering, and other factors.
DreamFactory vs. Node.js
I’m going to take a small detour here and discuss some of the differences between DreamFactory and Node.js. This is helpful background information in order to understand how DreamFactory can be scaled horizontally with multiple servers, load balancers, and clustered databases.
We considered using Node.js for the DreamFactory engine, but were concerned that a single thread would be insufficient to support a massively scalable mobile deployment. The workload in a sophisticated REST API platform is quite comparable to an HTML website written in Drupal or WordPress where multiple threads are required to process all the data.
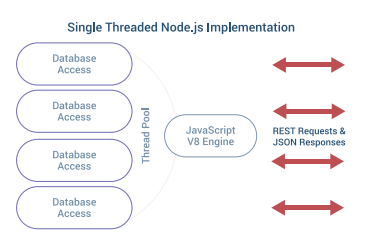
Another issue was the need for mature interfaces to a wide variety of SQL and NoSQL databases. This was a challenge with Node.js. Instead, we chose PHP because this language is in widespread use and has great frameworks such as Laravel. The main thing we liked about Node.js was the V8 engine. This allows developers to write JavaScript on the client and on the server. DreamFactory harnesses the power of the V8 engine by using the V8Js extension for PHP, except that DreamFactory runs it in parallel for scalability. The V8 engine is also sandboxed for security.
On an Apache server running DreamFactory, we use Prefork MPM to create a new child process with one thread for each connection. You need to be sure that the MaxClients configuration directive is big enough to handle as many simultaneous requests as you expect to receive, but small enough to ensure enough physical RAM for all processes.
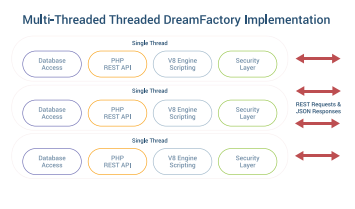
There is a danger that you will have more incoming requests than the server can handle. In this case, DreamFactory will issue an exponential backoff message telling the client to try again later. DreamFactory Enterprise offers additional methods of limiting calls per second. But still, the total number of transactions will be limited. Node.js can potentially handle a very large number of simultaneous requests with event-‐based callbacks, but in that situation you are stuck with a single thread for all of the data processing. In this situation, Node.js becomes a processing bottleneck for every REST API call.
If you expect a massive number of incoming requests, then consider running DreamFactory on an NGINX server with PHP-FPM instead of Apache. NGINX can maximize the requests per second that the hardware can handle, and reduce the memory required for each connection. This is a “best of both worlds” scenario that allows a conventional web server to handle massive transaction volumes without the processing bottleneck of Node.js.
Horizontal Scaling
This section discusses ways to use multiple servers to increase performance. The simplest model is just to run DreamFactory on a single server. When you do a Bitnami install, DreamFactory runs in a LAMP stack with the default SQL database and some local file storage. The next step up is to configure a separate server for the default SQL database. There are also SQL databases that are available as a hosted cloud service.
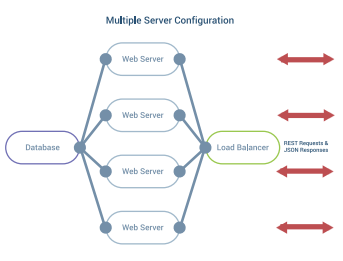
Multiple Servers
You can use a load balancer to distribute REST API requests among multiple servers. A load balancer can also perform health checks and remove an unhealthy server from the pool automatically. Most large server architectures include load balancers at several points throughout the infrastructure. You can cluster load balancers to avoid a single point of failure. DreamFactory is specifically designed to work with load balancers and all of the various scheduling algorithms.
DreamFactory uses JWT (JSON Web Token) to handle user authentication and session in a completely stateless manner. Therefore, a REST API request can be sent to any one of the web servers at any time without the need to maintain user session/state across multiple servers. Each REST API call to a DreamFactory Instance can pass JWT in the request header, the URL query string, or in the request payload. The token makes the request completely aware of its own state, eliminating the need to maintain state on the server.
Shared Local Storage
All of the web servers need to share access to the same local file storage system. In DreamFactory Version 1.9 and below, you will need a shared “storage” drive mounted with NFS or something similar. DreamFactory Version 2.0 and higher supports a more configurable local file system. The Laravel PHP Config File specifies a driver for retrieving files and this can be on a local drive, NFS, SSHFS, Dropbox, S3, etc. This simplifies multiple server setup and also PaaS delivery options.
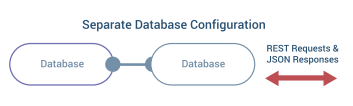
Multiple Databases
The default SQL database can be enhanced in various ways. You can mirror the database, create database clusters for enhanced performance, and utilize failover clusters for high-availability installations. A full discussion of this topic is beyond the scope of this paper.
Performance Benchmarks
Below are some results that show the vertical scalability of a single DreamFactory Instance calculated with Apache Benchmark. Five different Amazon Web Services EC2 instances were tested. The servers were t2.small, t2.medium, m4.xlarge, m4.2xlarge, and finally m4.4xlarge.
Vertical Scaling Benchmarks
For this test, we conducted 1000 GET operations from the DreamFactory REST API. There were 100 concurrent users making the requests. Each operation searched, sorted, and retrieved 1000 records from a SQL database. This test was designed to exercise the server side processing required for a complex REST API call.
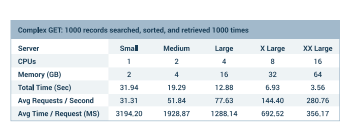
Looking at the three m4 servers, we see a nice doubling of capacity that matches the extra processors and memory. This really shows the vertical scalability of a single DreamFactory instance. The complex GET scenario highlights the advantages of the additional processor power.
Next, we tried a similar test with a simple GET command that basically just returned a single database record 5000 times. There were 100 concurrent users making the requests. In this situation, the fixed costs of Internet bandwidth, network switching, and file storage start to take over, and the additional processors contribute less.
Look at these results for 5000 simple GETs from the API. As you can see, performance does not fully double with additional processors. This demonstrates the diminishing returns of adding processors without scaling up other fixed assets.
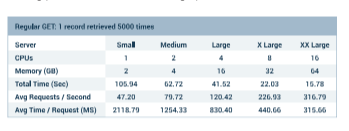
By the way, we also looked at POST and DELETE transactions. The results were pretty much what you would expect and in line with the GET requests tested above.
Horizontal Scaling Benchmarks
Below are some results that show the horizontal scalability of a single DreamFactory Instance calculated with Apache Benchmark. Four m4.xlarge Amazon Web Services EC2 instances were configured behind a load balancer. The servers were configured with a common default database and EBS storage.
First we tested the complex GET scenario. The load balanced m4.xlarge servers ran at about the same speed as the m4.4xlarge server tested earlier. This makes sense because each setup had similar CPU and memory installed. Since this example was bound by processing requirements, there was not much advantage to horizontal scaling.

Next we tested the simple GET scenario. In this case there appears to be some advantage to horizontal scaling. This is probably due to better network IO and the relaxation of other fixed constraints compared to the vertical scalability test.
Concurrent User Benchmarks
We also evaluated the effects of concurrent users simultaneously calling REST API services on the platform. This test used the complex GET scenario where 1000 records were searched, sorted, and retrieved. The test was conducted with three different Amazon Web Services EC2 instances. The servers were m4.xlarge, m4.2xlarge, and m4.4xlarge. We started with 20 concurrent users and scaled up to 240 simultaneous requests.
The minimum time for the first requests to finish was always around 300 milliseconds. This is because some requests are executed immediately and finish first while others must wait to be executed.
The maximum time for the last request to finish will usually increase with the total number of concurrent users. Based on the processor size, the maximum time for the last request can increase sharply past some critical threshold. This is illustrated by the 8 processor example, where maximum request times spike past 160 concurrent users.
The 16 processor server never experienced any degradation of performance all the way to 240 concurrent users. This is the maximum number of concurrent users supported by the Apache Bench test program. Even then, the worst round trip delay was less than 1⁄2 second. Imagine a real world scenario with 10,000 people logged into a mobile application. If 10% of them made a service request at the same time, you would expect a round trip delay of 1⁄2 second on average and a full second in the worst case.
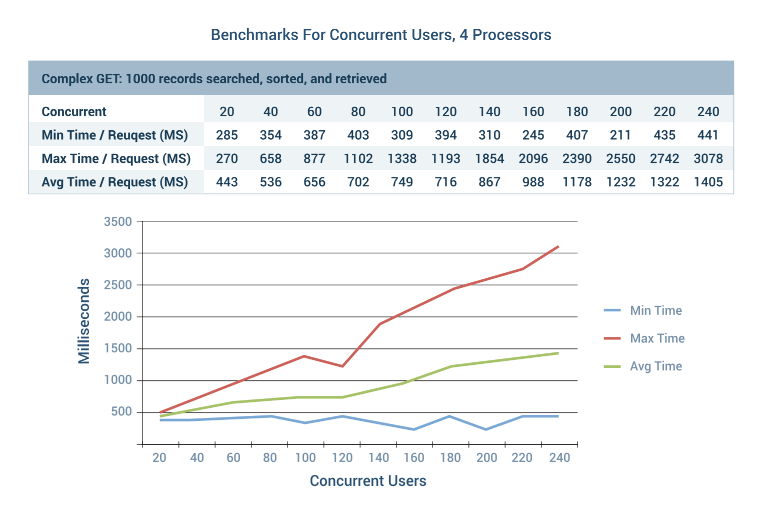
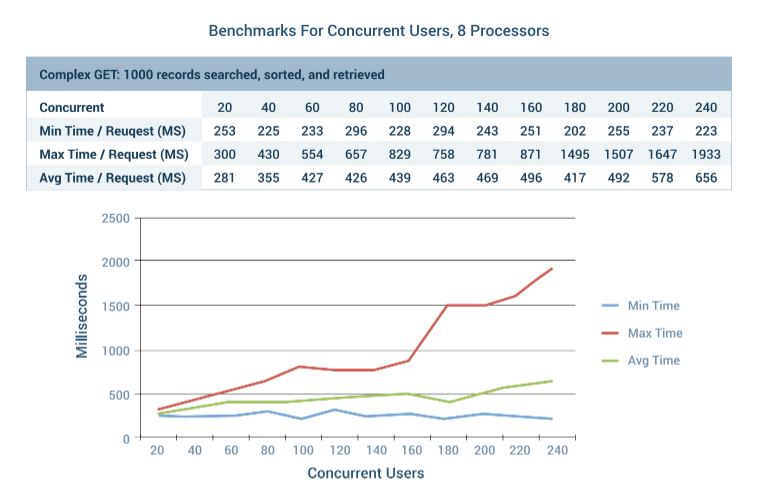
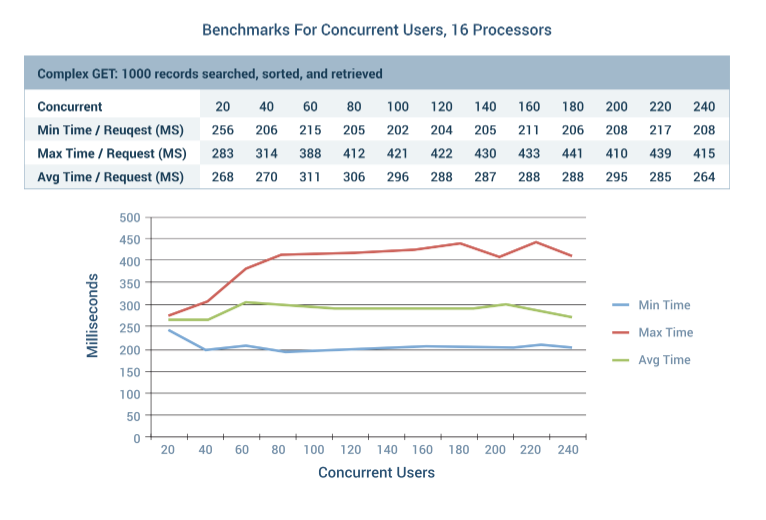
Your Mileage May Vary
For your implementation, we recommend getting a handle on the time required to complete an average service call. This could depend on database speed, server side scripting, network bandwidth, and other factors. Next, experiment with a few server configurations to see where the limits are. Then scale the implementation to the desired performance characteristics for your application.
In all of my benchmarking tests, there were never any unexplained delays or other performance characteristics that did not respond in a scalable manner. The addition of horizontal or vertical hardware will scale DreamFactory 3.0 in a linear fashion for any requirements that you may have.
Cloud Scaling
Most of the Infrastructure as a Service (IaaS) vendors have systems that can scale web servers automatically. For example, Amazon Web Services can scale EC2 instances with Auto Scaling Groups and Elastic Load Balancers. Auto scaling is built into Microsoft Azure and Rackspace as well. If you want to deploy in the cloud, then check with your vendor for the options they support.
We discussed Platform as a Service (PaaS) deployment options earlier. These systems do not support persistent local file storage, but the trade-‐off is that your application instance is highly scalable. You can simply specify the maximum number of instances that you would like to run. As traffic increases, additional instances are brought online. If a server stops responding, then the instance is simply restarted.
Conclusion
DreamFactory is designed to be scaled like a simple website. DreamFactory supports the standard practices for scaling up with additional server capabilities and out with additional servers. DreamFactory has installers or installation instructions for all major IaaS and PaaS clouds, and some of these vendors automatically handle scaling for you.